Visual affordance segmentation identifies the surfaces of potential interaction with an object in an image. The
variety of the geometry and physical properties of objects as well as occlusions are common challenges for the
identification of affordances. Occlusions of objects that are hand-held by a person is a particular challenge
when people are manipulating an object. To address this challenge, we propose an affordance segmentation model
that uses auxiliary branches to focus on the object and hand regions separately. The proposed model learns
affordance features under hand-occlusion by weighting the feature map through hand and object segmentation. To
train the proposed model, we annotated the visual affordances of an existing dataset with mixed-reality images
of hand-held containers in third-person (exocentric) images. Experiments on both real and mixed-reality show
that our model achieves better affordance segmentation and generalisation than existing models.
We name our proposed model Arm-Container Affordance Network (ACANet) as we consider containers for food and
drinks, and graspable and contain as affordance classes. Assuming as input the image with at
the center a
correctly detected object of interest, the model identifies the classes background, and arm,
graspable and contain.
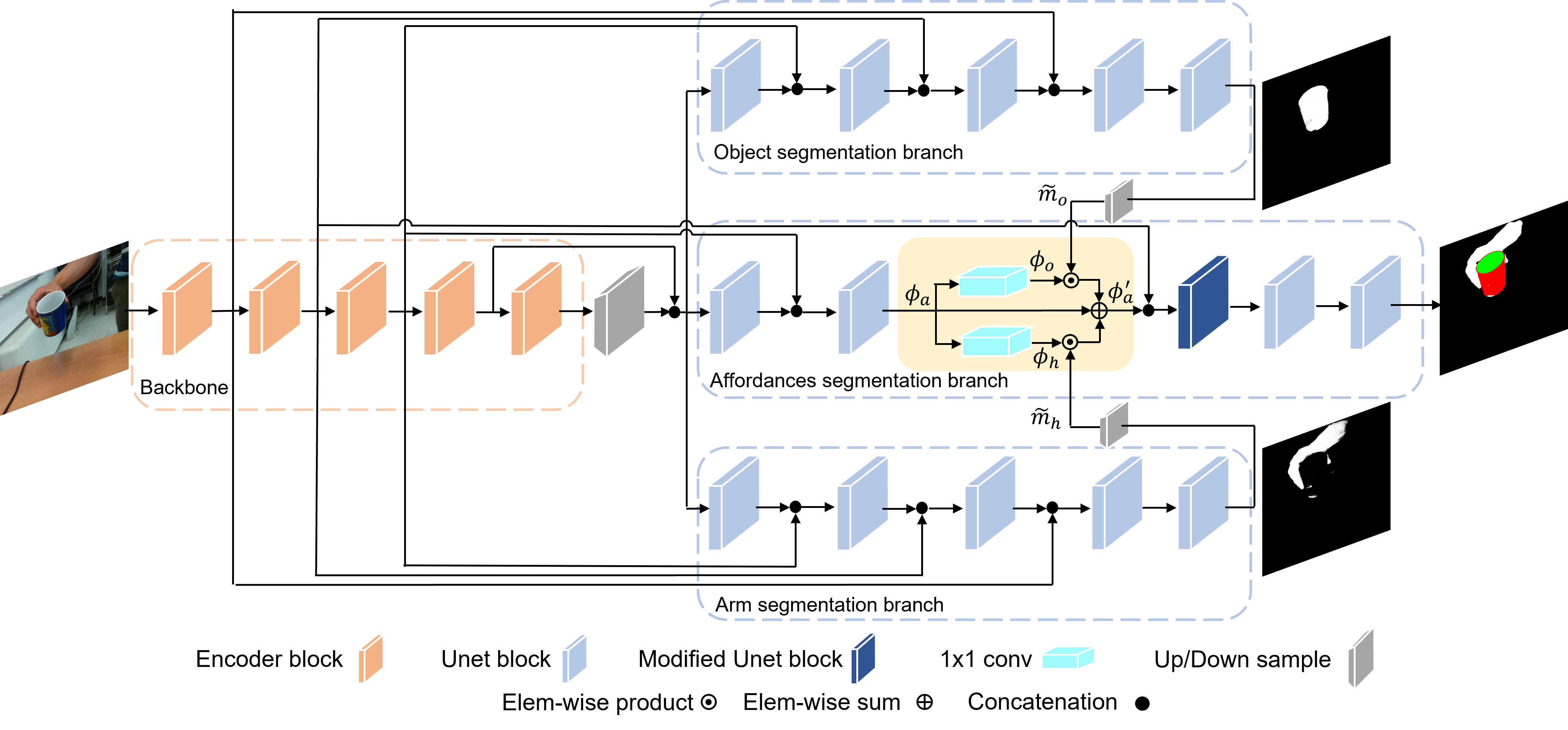
ACANet uses a multi-branch architecture to predict object and hand segmentation, and a fusion module to learn
separate sets of features in the hand and object region. The additional segmentation branches
specialise in the segmentation of the arm and of the visible region of the object. Segmenting the object helps
the model learn the area of the image where the affordances are. To learn specialised features in the object and
arm regions, we project the affordance features φa into two different feature spaces
maintaining the same dimensionality, φo and φh, by using C'
convolutional filters 1x1 to combine each pixel position independently. We then perform a pixel-wise weighting
of the feature maps φo and φh with the corresponding segmentation mask
mo and mh, i.e., features outside of the predicted object (or arm)
region are highly penalised.
We complement CORSMAL Hand-Occluded Containers (CHOC), which has
mixed-reality images of hand-occluded containers, with visual affordance annotations.
Data and annotation are available at CHOC webpage.
We show results arm and affordances results of models on a subset of the real data test set.
If you use the data, the code, or the models, please cite:
Affordance segmentation of hand-occluded containers from exocentric images
T. Apicella, A. Xompero, E. Ragusa, R. Berta, A. Cavallaro, P. Gastaldo
IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), 2023
@inproceedings{apicella2023affordance,
title={Affordance segmentation of hand-occluded containers from exocentric images},
author={Apicella, Tommaso and Xompero, Alessio and Ragusa, Edoardo and Berta, Riccardo and Cavallaro, Andrea and Gastaldo, Paolo},
booktitle={IEEE/CVF International Conference on Computer Vision Workshops (ICCVW)},
year={2023},
}
If you have any further enquiries, question, or comments, please contact
tommaso.apicella@edu.unige.it