About me
I am a PostDoc in the PAVIS group at the Istituto Italiano di Tecnologia (IIT).
The main focus of my research activity is the design of computer vision models that enable robots to explore and interact with objects
or people in the environment.
Before joining IIT, I was a PhD student in Interactive and Cognitive Environments, a joint Doctorate between University of Genoa and Queen Mary University of London. The main topic of my PhD research was Affordance Segmentation that identifies the surfaces of potential interaction between an agent (e.g. a robotic hand) and an object relying only on visual information. The exciting and fascinating aspect of Affordance Segmentation is the connection to robotic and prosthetic applications, enabling assistive technologies (e.g., grasping, object manipulation) or collaborative human-robot scenarios.
Before joining IIT, I was a PhD student in Interactive and Cognitive Environments, a joint Doctorate between University of Genoa and Queen Mary University of London. The main topic of my PhD research was Affordance Segmentation that identifies the surfaces of potential interaction between an agent (e.g. a robotic hand) and an object relying only on visual information. The exciting and fascinating aspect of Affordance Segmentation is the connection to robotic and prosthetic applications, enabling assistive technologies (e.g., grasping, object manipulation) or collaborative human-robot scenarios.
Research interests
Embodied AI | Computer Vision | Machine Learning | Multimodal fusion | Affordance prediction
Reviewing service
Awards
- Outstanding Reviewer, Computer Vision and Pattern Recognition (CVPR), 2026
875 out of 17,491 reviewers (top 5%)
[link] - Outstanding Reviewer, British Machine Vision Conference (BMVC), 2024
166 out of 860 reviewers (top 19%)
[link]
Conferences
- Computer Vision and Pattern Recognition (CVPR): 2025, 2026
- European Conference on Computer Vision (ECCV): 2024 (helped reviewing 1 paper), 2026
- Conference on Robot Learning (CoRL): 2025
- British Machine Vision Conference (BMVC): 2024
Latest works
|
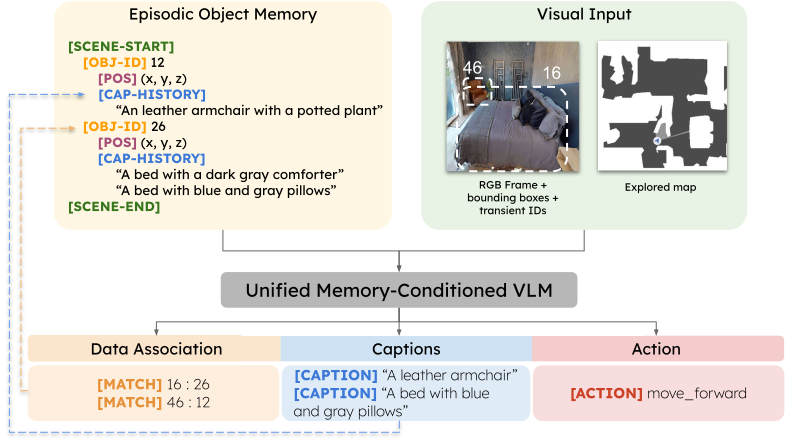
Memory-Augmented Vision-Language Agents for Persistent and Semantically Consistent Object Captioning
T. Galliena, S. Rosa, T. Apicella, P. Morerio, A. Del Bue, L. Natale Under review, 2026 [arXiv] [website] |
|
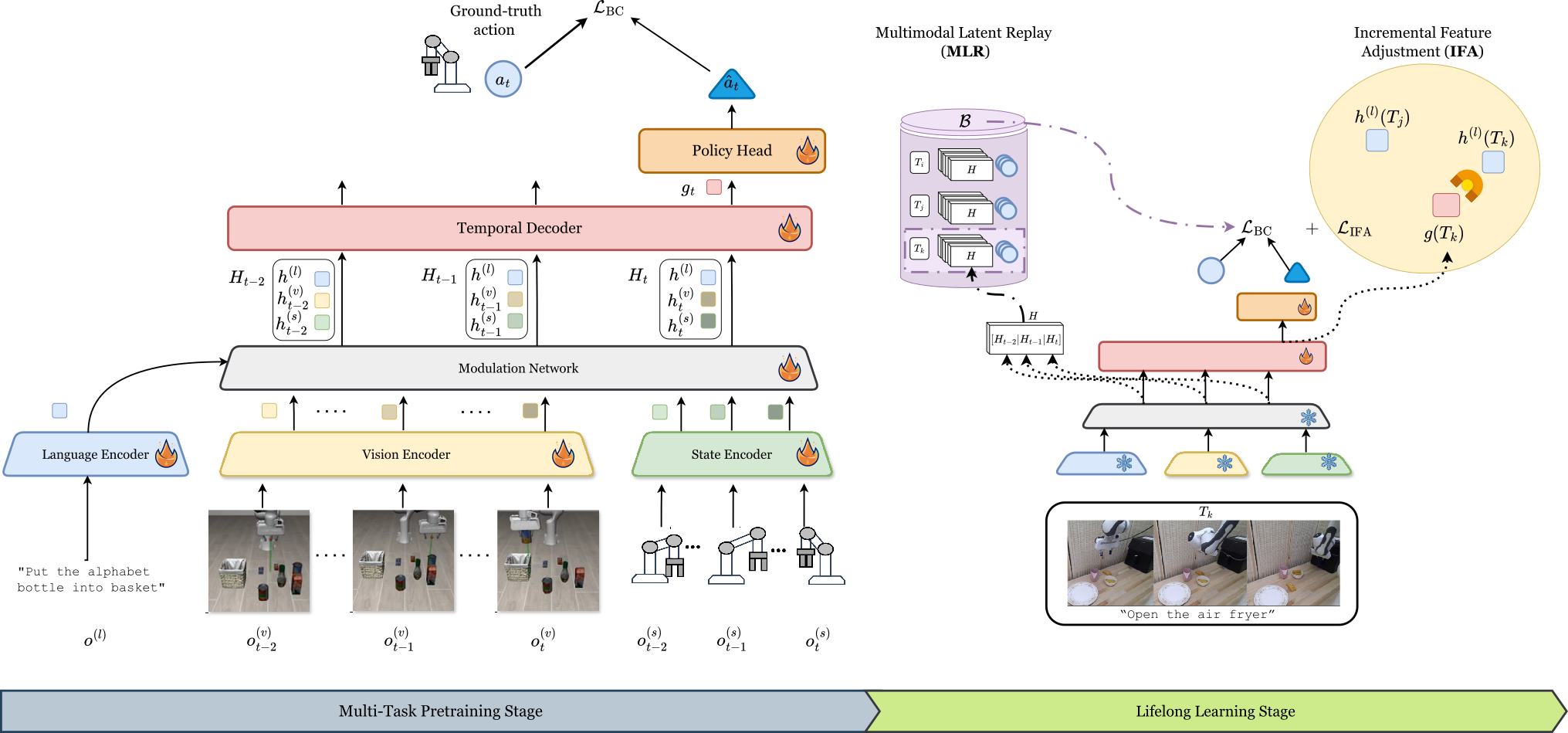
Lifelong Imitation Learning with Multimodal Latent Replay and Incremental Adjustment
F. Yu, M. Tiezzi, T. Apicella, C. Beyan, V. Murino Conference on Computer Vision and Pattern Recognition (CVPR), 2026 [arXiv] |
|
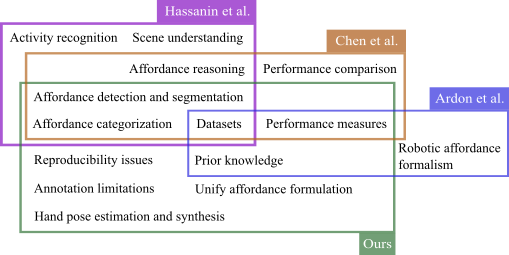
Visual Affordance Prediction: Survey and Reproducibility
T. Apicella, A. Xompero, A. Cavallaro Under review, 2025 [arXiv] [website] [repository] |
|
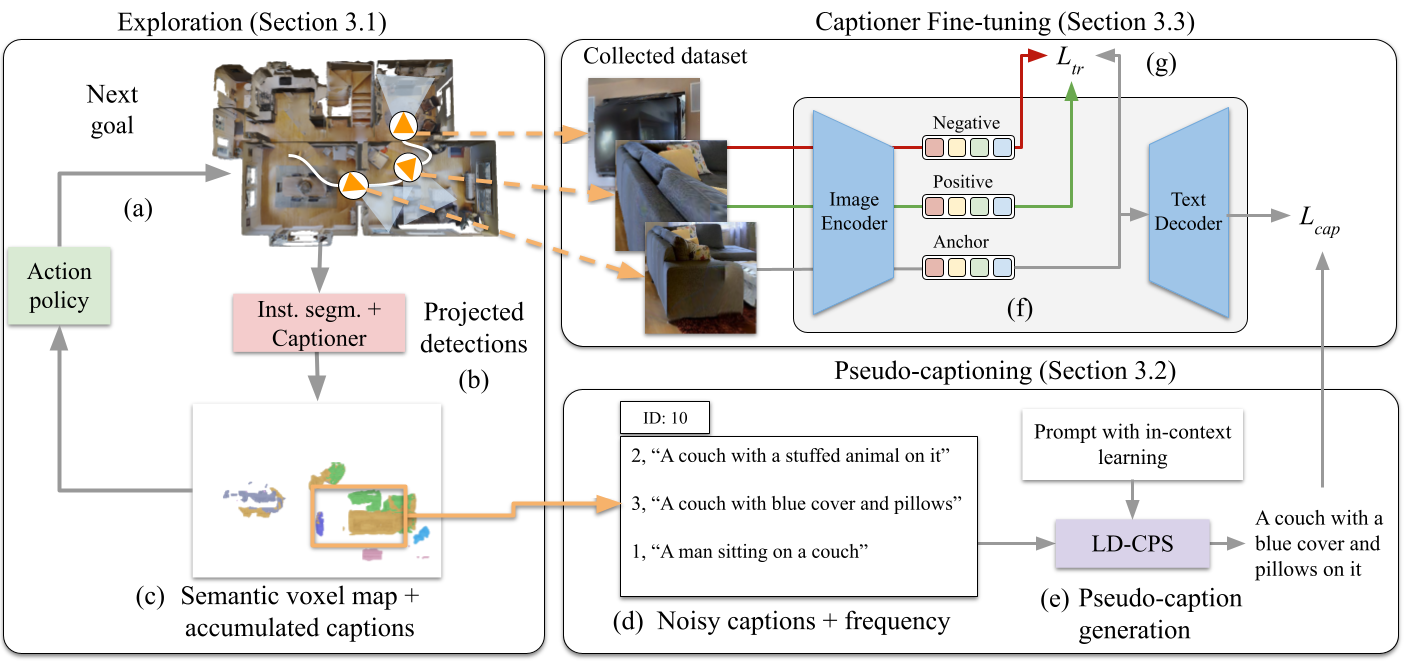
Embodied Image Captioning: Self-supervised Learning Agents for Spatially Coherent Image Descriptions
T. Galliena, T. Apicella, S. Rosa, P. Morerio, A. Del Bue, L. Natale International Conference on Computer Vision (ICCV), 2025 [arXiv] [website] [code] [testing set] |
|
Segmenting Object Affordances: Reproducibility and Sensitivity to Scale
T. Apicella, A. Xompero, P. Gastaldo, A. Cavallaro European Conference on Computer Vision Workshops (ECCVW), 2024 [arXiv] [website] [code] [trained models] |